
In February this year we had our first session on SSIS & HDInsight at our “Deutsche SQL Server Konferenz 2014”. By the way, the next conference will take place on the 3.-5. Februrary 2015, have a look here.
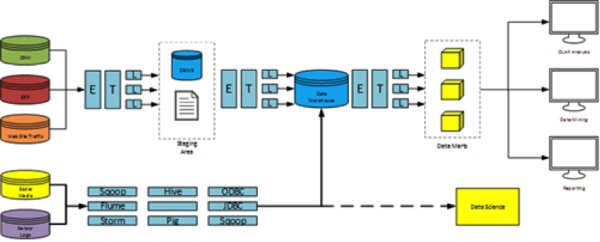
The main focus of that session was not from a technical perspective of HDInsight or a Big Data project, it was more about how both worlds can work together, what do you need to create a closed loop approach and where to start. Therefore we showed among other things the following workflow as a combination of a traditional ETL process and a Big Data solution.

This workflow is nothing really new nor something we reinvented. You can find this or similar processes, with different product names on it, by nearly all Big Data solution providers. From Microsoft you can find a similar process in the whitepaper Developing big data solutions on Microsoft Azure HDInsight [eBook Download].
Again, our approach to this process is more the combination of both worlds, as we believe both worlds have to move together and each technique has its advantages. The trick is how you can do it together, as we think processes like these can happen in combination, where one belongs to another. So our idea was to combine SSIS with HDInsight and use SSIS as control flow for all these steps. With this idea in mind we have used different Script Tasks in SSIS. Because a good API is offered by Microsoft, the integration was very easy. Unfortunately you still had to fight with some peculiarities of SSIS. To work together with Nuget and SSIS script tasks is not pleasant.
To enhance a bit our session and to bring the integration of SSIS and Big Data scenarios forward, we have started implementing these script tasks as Control Flow tasks. And sometimes if you start coding something, you get more ideas, more knowledge of the technology, more and more ideas and you can get lost in it… 🙂
Instead of just 3 or 4 components we’re now developing a whole series of tasks. Our development focus is not on getting a functional complete and (totally) bug free set of tasks. At the moment we are concentrating on different tasks to see what is possible, what make sense, how can we improve performance and how can we integrate these tasks into something like the above described process. So far we’ve developed the following tasks:
| Azure Blob Client With this SSIS Task you have the possibilities to upload and download data from and to an Azure Blob storage Container. For performance improvements the upload process is implemented as a multi-threaded segmented file uploader. So we can transfer 1GB data in a single file in under 45 seconds from a demo Azure VM to a Blob Container. 1GB in 145 files takes about 1:30 minutes. The download process will be implemented in the same way in the future, but it is single threaded and without segments at the moment. |
|
| Azure Storage Container This task can create and delete a storage container into an existing Azure Storage. |
|
| HDInsight Cluster The HDInsight Cluster Task creates or deletes a HDInsight Cluster in your existing subscription. At the moment you can create a Hadoop cluster in different versions (2.1, 3.0, 3.1) or a HBase cluster. You can also specify the cluster size, head node size as well as the region of your cluster. |
|
| Hive With the Hive Task it is possible to execute a Hive query against an existing HDInsight Cluster. |
|
| Map Reduce Job The Map Reduce Task let you execute a Map Reduce Job on your HDInsight cluster. In addition to the cluster and the storage, the mapper and reducer also need to be defined. This task has only been tested on compatibility with C# map reduce jobs.PigThe Pig Task is similar to the Hive Task. But instead of HiveQL you can run Pig Latin on your HDInsight cluster. |
|
| sqoop With the sqoop Task you can easily import/export data from or into your HDInsight cluster using Apache sqoop. The task itself supports almost all sqoop commands. In addition, you can overwrite the task with a manual sqoop command. The task has been tested only with SQL Server. |
In a really early stage we are testing the following components:
|
|
DocumentDB With the DocumentDB Task it is possible to store a Json File directly into the newly announced DocumentDB or you can save the result of a query into a JSON file. |
Our idea is to build a complete set of open source tasks. It’s possible that in the future we will release additional versions like a commercial open source version with special features or support. But for now we hope to cover everything major you need to address this technology from inside SSIS.
We would be very happy if you give us input on the components! Do you think it make sense, do you see these two technologies in combination or still as stand alone processes?
