

Bereits in meinem vorherigen Blog habe ich immer mal wieder ein paar Beiträge zu dem Thema CDC geschrieben. Nach wie vor ist das Thema CDC (Change Data Capture) auch in den verschiedensten Projekten von sehr großer Bedeutung, nicht nur bei BI Projekten.
CDC beschreibt im Wesentlichen ein Design Pattern um geänderte Daten (Insert/Update/Delete) in einer Datenbank zu ermitteln. Viele relationale Datenbanken haben Change Data Capture Technologien implementiert. Je nach Implementierung werden Änderungen direkt aus den Logfiles gelesen oder das RDBMS stellt direkt entsprechende Tabellen zur Verfügung, die es ermöglichen die Änderungen in einem relationalen Format leicht zu konsumieren. Oracle stellt entsprechende Funktionalitäten z.B. über den LogMiner zur Verfügung, der eine SQL-Schnittstelle auf die Redo-Log-Dateien bietet.
Beim SQL Server wurde CDC bereits mit der Version 2008 eingeführt. ich habe die Technologie besonders in Verbindung mit den SQL Server Integration Services zuerst mit Komponenten von der Firma Attunity eingesetzt. Seit der Version 2012 liefert Microsoft diese Komponenten selber zusammen mit dem SQL Server in einer OEM Version aus.
Attunity hatte sich zu diesem Zeitpunkt auf sein neues Produkt Replicate konzentriert, welches aus meiner Sicht speziell im Punkt Benutzerfreundlichkeit unschlagbar war. Seit der Übernahme von Attunity durch Qlik wird das Produkt entsprechend unter dem Qlik Replicate vertrieben.
- Mittlerweile gibt es viele verschiedene Anbieter auf dem Markt, die verschiene CDC Lösungen bereitstellen:
- https://www.equalum.io/
- https://striim.com/
- https://hvr-software.com
- http://gamma-soft.com
- https://syniti.com
- MySQL
- MongoDB
- PostgreSQL
- Oracle
- SQL Server
- Cassandra
- DB2
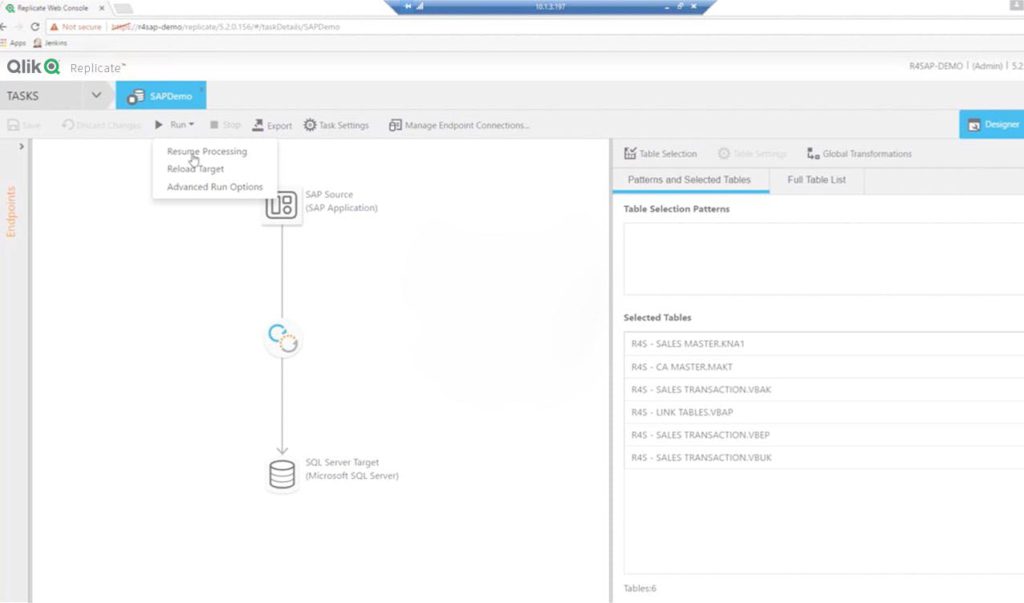
- Vitess
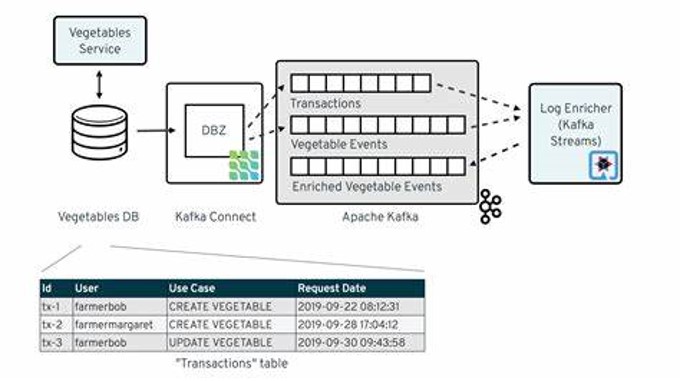
Der Vegetable Service sowie die Vegetable DB stellen hier eine Beispiel Anwendung und eine Beispiel Datenbank dar, deren Änderungen in der Datenbank via Debezium und Kafka Connect über Kafka an einen Endpunkt gestreamt werden können.
Wie Debezium aufgesetzt und konfiguriert werden kann, werde ich hier in weiteren Post noch einmal näher beschreiben. Aktuell möchte ich dafür erstmal auf einen etwas älteren Artikel von Davide Mauri verweisen: SQL Server Change Stream. Responding to data changes in real time… Auf GitHub stellt Davide auch einige Scripts zur Verfügung, um Debezium schnell mit Docker aufzusetzen.
Da Debezium aus der Open Source Welt kommt, sind neben dem Beitrag von Davide bisher nicht besonders viele Informationen zu finden, wie Debezium im Microsoft und speziell im Azure Kontext aufgesetzt und verwendet werden kann.
Eine Referenzarchitektur, die wir akuell verwenden, könnte dabei wie folgt aussehen:
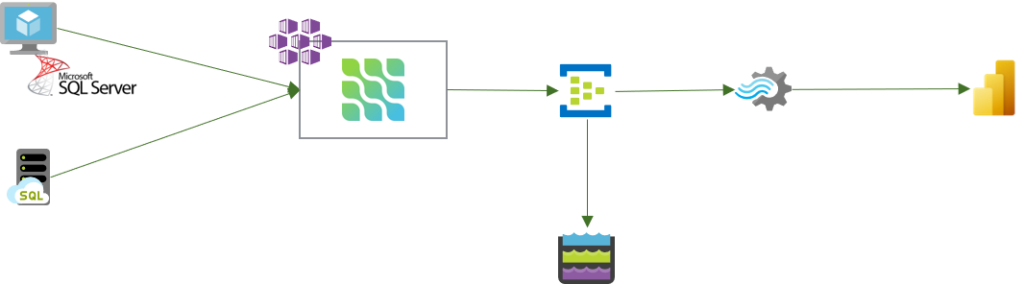
In dieser Architektur setzen wir als Quellsystem einen SQL Server auf einer Azure VM oder eine Azure Managed Instance ein. Debezium läuft innerhalb eines Azure Kubernetes Services.
Der Azure Event Hub ist im Standard Tier protokollkompatibel mit der Apache Kafka-Serverversion 1.0 und höher und kann entsprechend Daten von Debezium empfangen bzw. als Senke von Debezium verwendet werden und diese Daten weiterverarbeiten. In unserer Architektur werden die Daten direkt gecaptured und in einem Storage Account im AVRO Format gespeichert. Durch die Speicherung der Daten in einem Storage Account, können wir sicherstellen, dass die verschiedenen Events langfristig gespeichert werden. Über den Event Hub selber kann ansonsten immer nur auf Daten der max. letzten 7 Tage zugegriffen werden.
Danach setzen wir Stream Analytics ein, um die Daten aus dem Event Hub weiter zu verarbeiten und an ein Power BI Realtime Dataset zu senden. Power BI ist hier aber nur ein Beispiel Service. Stream Analytics Jobs können aktuell Daten an über 10 verschiedene Destionations senden: Outputs from Azure Stream Analytics | Microsoft Docs
