
Die aktuelle Version der Microsoft Data Quality Services wird mit einer SSIS DQS Cleansing Komponente ausgeliefert. Mit Hilfe der Komponente können Daten innerhalb des Datenflusses mit einer bestehenden Knowledge Base geprüft, bereinigt und angereichert werden.
Leider bestand bisher jedoch keine Möglichkeit mit SSIS die Dublettensuche der Data Quality Services zu nutzen. Ein Feature, das nach Aussagen des Microsoft DQS Teams auf Platz #1 der Kunden Requests stand.
Stand auf Platz #1? Jawohl, stand auf Platz #1 🙂 Denn in der letzten Woche haben wir bei Codplex unsere SSIS DQS Matching Transformation Komponente veröffentlicht.
Die Komponente ermöglicht es direkt innerhalb des Datenflusses eine Dublettensuche mit einer Knowledge Base und den darin enthaltenen Matching Policies auf den Data Quality Services durchzuführen.
Installation der Komponente
Die jeweils aktuelle Version der Komponte kann bei Codeplex als MSI File heruntergeladen werden.
Das Setup besteht lediglich aus einem kleinen Wizard in dem die Microsoft Public License (Ms-PL) aangenommen werden muss.
Die entsprechenden Installationsverzeichnisse sind quasi durch die Integration Services vorgegeben, zum einen wird die Komponente dem GAC hinzugefügt, zum anderen werden die Datein in das Verzeichnis %PROGRAMMFILES(x86)%\Microsoft SQL Server\110\DTS\PipelineComponents\ kopiert – auf einem x86-System entsprchend %PROGRAMFILES%.
Mit SQL Server 2012 ist es nicht mehr notwendig die Komponente extra der Toolbox innerhalb der SQL Server Data Tools hinzuzufügen, die Komponente sollte automatisch im Bereich Common erscheinen. Waren die SSDT während der Installation geöffnet, kann die SSIS Toolbox ganz einfach über einen rechten Mausklick und dem Menüpunkt Refresh Toolbox aktualisiert werden.

Für die SQL Server Data Tools – Business Intelligence for Visual Studio 2012 ist das vorgehen identisch, hier existieren keine Unterschiede.
Konfiguration der Komponente
Als erstes benötigt die Komponente einen Eingang. Sollen Daten aus unterschiedlichen System mit einander verbunden werden, so müssen diese vorher mit einer UNION ALL Komponente zusammengeführt werden, die Komponente unterstützt nur einen Eingang. Die Konfiguration kann wwie üblich per Doppelklick auf die Komponente gestartet werden.
Connection Manager
Im ersten Schrit wird dazu entweder ein bestehender DQS Connection Manager ausgewählt, oder über die Schaltfläche New ein neuer erstellt. Die erstellten Connection Manager werden seitens der Entwicklungsumgebung immer mit “DQS Cleansing Connection Manager” am Anfang benannt. Hierdurch sollte man sich nicht verwirren lassen, dies hängt damit zusammen, dass die ursprüngliche Implementierung seitens Microsoft lediglich für den Bereich Cleansing angedacht war. Nach der Auswahl eines Connecton Managers, muss in der zweiten ComboBox eine Knowledge Base ausgewählt werden. Die in der jeweiligen Knowledge Base angelegten Matchingg Poilicies werden im unteren Bereich als Treeview angezeigt.

Wie im Screenshot zu sehen ist, werden sowol Domains wie auch Composite Domains angezeigt. Bei der Matching Policy Address werden im obigen Screenshot jedoch nur Composite Domains angezeigt. Dies hängt damit zusammen, das bei der entsprechenden Policy die Gewichtung direkt auf die beiden Composite Domains gesetzt wurde und nicht auf dien einzelnen Domains.

Mapping
Im Tab Mapping werden die eingehenden Spalten aus dem Datenfluss den Domains innerhalb der Knowledge Base zugeordnet. Wird eine nicht zugeordnete Eingabespalte im obigen DataGrid ausgewählt, so erscheint diese Spalte im unteren Mneü und kann dort einer Domain aus der Matching Policy zugeorndet werden.

Wird eine Domain, die Bestandteil einer Composite Domain ist, einer Input Column zugeordnet, so kann die Composite Domain nicht mehr ausgewählt. Umgekehrt stehen die Domains einer Composite Domain nicht mehr zur Verfügung, sobal die Composite Domain einer Input Column zugeordnet wurde.
Unabhängig der ausgewählten Spalten, werden immer alle Eingangsspalten auch wieder in den Datenfluss zurückgeschrieben.
Advanced
Im Bereich Advanced kann zusätzlich der Minimal Matching Score definiert werden. Hierbei ist zu beachten, dass diese Einstellung nicht in die vorhandene Matching Policy auf dem DQS eingreift. Der Minimal Matching Score agiert als Filter auf die zu ladenden Dubletten aus den Data Quality Services.
Ist der Minimal Matching Score innerhalb der Matching Policy auf 80 gesetzt, so werden alle Datensätze die einer Übereinstimmung von 80% zueinander haben als Dubletten gekennzeichnet. Wird der Minimal Matching Score innerhalb der Komponente auf 90% gesetzt, so werden aus der gefundenen Menge nur die Dubletten zurück in den Datenfluss geladen, der Matching Score mindestens 90% beträgt. Alle Dubletten mit einem Score zwischen 80% und 90% werden auf dem Server belassen und nicht zurück in den Datenfluss geschrieben.

Wie im Screenshot zu sehen, ist die Einstellung Cleanup DQS project after execution ausgewählt aber die Checkbox deaktiviert. In der aktuellen Version wird ein durch die Komponente erstelltes DQS Matching Projekte nach der Ausführung direkt wieder auf dem vom Server gelöscht. Für eine spätere Version ist geplant hier auch das Löschen auf dem Server zu unterbinden, so dass die Projekt über den DQS Client noch einmal geöffnet werden können.
Output
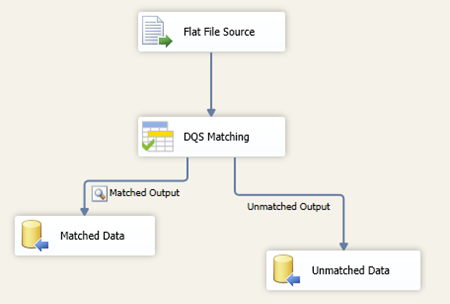
Die Komponente verfügt standardmäßig über 2 Ausgänge, Matched Output und Unmatched Output. Der Unmatched Output enthält alle Datensätze zu denen keine Dublette existiert. Der Matched Output enthält alle Datensätze zu denen mindestens eine Dublette auf Basis der Matching Policies der gewählten Knowledge Base besteht.

Den Matched Output Daten werden zusätzlich zu den Eingangsspalten die folgenden weitere Spalten hinzugefügt.
| RecordId | Eindeutige ID des Datensatzes |
| ClusterId | Dublettengruppe; Alle Datensätze mit der selben ClusterId sind potentielle Dubletten zueinander |
| ClusterRecordRelationId | Eindeutige ID des Datensatz innerhalb des Matched Output |
| MatchingScore | Der Matching Score zwischen zwei Datensäzen |
| RuleId | Die eindeutige ID einer Regel, mit der der Datensatz den entsprechenden Matching Score erzielt hat |
| IsPivot | True kennzeichnet die Kopfdublette innerhalb einer Dublettengrupe, Flase definiert die Folgedubletten |
| Status | Der Status der aktuellen potenitellen Dublette; hier immer Approved |
| PairId | Eindeutige ID innerhalb der Folgedubletten; Kopfdubletten (IsPivot) werden mit 0 gekennzeichnet |
| SiblingId | ID der Kopfdublette innerhalb der Dublettengruppe |
| PivotId | Die ID des Pivot records des Clusters |
Die beiden Ausgänge der Komponente müssen nicht zwingend einer nachfolgenden Komponente zugeordnet werden.
Links
Ein weiterer sehr guter Artikel zu unserer SSIS DQS Matching Transformation Komponente ist von Welly Lee, Programm Manager SQL Server Data Quality Services , im DQS Team Blog erschienen: Automating the data matching process in SQL Server Data Quality Services (DQS)
Weitere gute Blog-Beiträge zum Thema Data Matching mit DQS sind hier zu finden:
